Query Engine
Query engine
The QuestDB Query Engine includes A custom SQL parser, a just-in-time (JIT) compiler, and a vectorized execution engine to process data in table page frames for better CPU use.
SQL parsing & optimization
-
Custom SQL parser: The parser supports QuestDB's SQL dialect and time-series extensions. It converts SQL queries into an optimized abstract syntax tree (AST).
-
Compilation pipeline: The engine compiles SQL into an execution plan through stages that push down predicates and rewrite queries to remove unnecessary operations.
-
Optimization techniques: The planner applies rule-based rewrites and simple cost estimations to choose efficient execution paths.
-
Columnar reads: Table columns are randomly accessible. Columns with fixed size data types are read by translating the record number into a file offset by a simple bit shift. The offset in the column file is then translated into an offset in a lazily mapped memory page, where the required value is read from.

Execution model
- Operator pipeline: The execution plan runs as a series of operators (filters, joins, aggregators) in a tightly integrated pipeline.
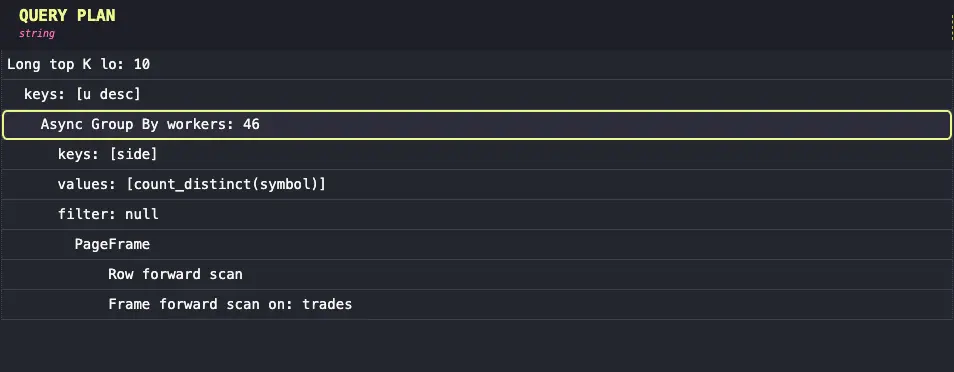
-
JIT compilation and Vectorized processing: Queries with a
WHEREclause compile critical parts of the execution plan to native machine code (SIMD AVX-2 instructions) just in time. Vectorised instructions apply the same operation to many data elements simultaneously. This maximizes CPU cache use and reduces overhead. -
Multi-threaded execution: On top of the JIT, QuestDB tries to execute as many queries as possible in a multi-threaded, multi-core fashion. Some queries, for example those involving an index, are executed on a single thread. Other queries, like those involving
GROUP BYandSAMPLE BY, execute a pipeline with some single-threaded stages and some multi-threaded stages to avoid slow downs when groups are unbalanced. -
Worker pools: QuestDB allows to configure different pools for specialized functions, like parsing incoming data, applying WAL file changes, handling PostgreSQL-Wire protocol, or responding to HTTP connections. By default, most tasks are handled by a shared worker pool.
-
Query plan caching: The system caches query plans for reuse within the same connection. (Query results are not cached.)
-
Column data caching: Data pages read from disk are kept in system memory. Sufficient memory prevents frequent disk reads.
Next Steps
- Back to the QuestDB Architecture overview
- QuestDB GitHub Repository
- QuestDB Documentation