Storage Engine
Storage engine
The QuestDB Storage Engine implements a row-based write path for maximum ingestion throughput, and a column-based read path for maximum query performance.
Parallel Write-Ahead-Log
-
Two-phase writes: All changes to data are recorded in a Write-Ahead-Log (WAL) before they are written to the database files. This means that in case of a system crash or power failure, the database can recover to a consistent state by replaying the log entries.
-
Commit and write separation: By decoupling the transaction commit from the disk write process, a WAL improves the performance of write-intensive workloads, as it allows for sequential disk writes which are generally faster than random ones.
-
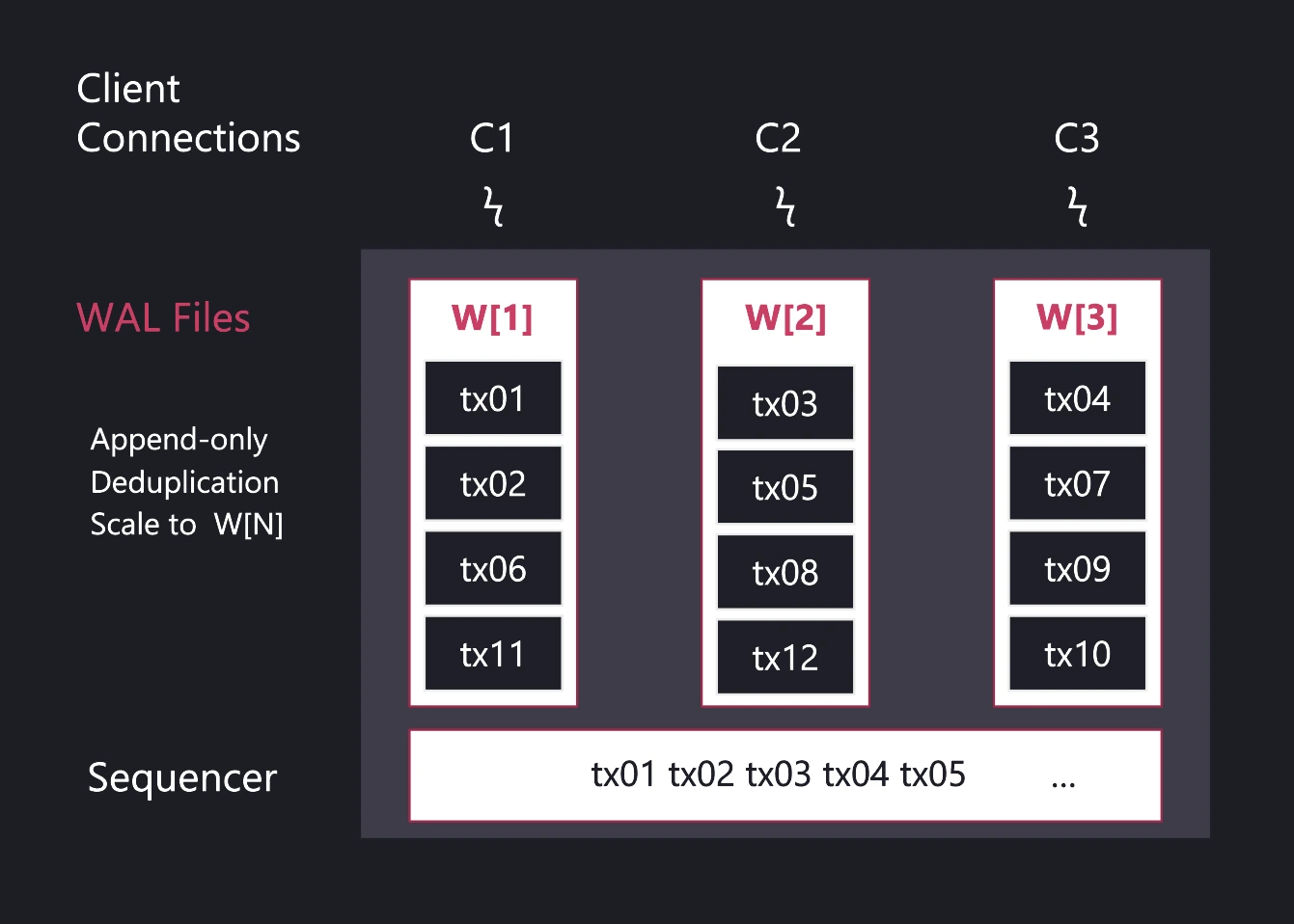
Per-table WAL: WAL files are separated per table, and also per active connection, allowing for concurrent data ingestion, modifications, and schema changes without locking the entire table.
-
WAL Consistency: QuestDB implements a component called "Sequencer", which ensures that data appears consistent to all readers, even during ongoing write operations.
-
TableWriter: Changes stored in the WAL, is stored in columnat format by the TableWriter, which can handle and resolve out-of-order data writes, and enables deduplication. Column files use an append model.
Data Deduplication
When enabled, data deduplication works on all the data inserted into the table and replaces matching rows with the new versions. Only new rows that do no match existing data will be inserted.
Generally, if the data have mostly unique timestamps across all the rows, the performance impact of deduplication is low. Conversely, the most demanding data pattern occurs when there are many rows with the same timestamp that need to be deduplicated on additional columns.
Column-oriented storage
- Data layout:
The system stores each table as separate files per column. Fixed-size data types use one file
per column, while variable-size data types (such as
VARCHARorSTRING) use two files per column.

-
CPU optimization: Columnar storage improves CPU use during vectorized operations, which speeds up aggregations and computations.
-
Compression: Uniform data types allow efficient compression that reduces disk space and speeds up reads when ZFS compression is enabled. Parquet files generated by QuestDB use native compression.
Next Steps
- Back to the QuestDB Architecture overview
- QuestDB GitHub Repository
- QuestDB Documentation